Héberger sa propre solution d'IA générative agentique
(Avril 2026)
Dans un contexte où les questions de souveraineté et de confidentialité
sont de plus en plus présentes, comment héberger sa propre solution d'IA
générative ?
Ces solutions d'auto hébergement peuvent également selon les besoins
présenter un intérêt économique en permettant de se passer d'abonnements
à des fournisseurs de "tokens" IA.
Je me suis donc intéressé dans cet article à la mise en place d'une
infrastructure d'hébergement pour des applications d'IA générative,
d'agents, d'assistants de code etc.
Le matériel
Qui dit auto-hébergement dit serveur, pour ce qui est du matériel cela
va dépendre des besoins en capacité de calcul ainsi que du budget.
Il y a deux aspects à prendre en compte :
- La puissance de calcul.
- la quantité de mémoire.
En terme de puissance de calcul il est possible d'obtenir à l'heure
actuelle des performances acceptables en utilisant un CPU puissant avec
de nombreux coeurs, cependant, les GPU restent généralement plus
performants dans ce domaine. La quantité de mémoire quant à elle va
déterminer la taille du modèle et du contexte que le serveur sera
susceptible d'héberger. Utiliser son CPU permet en outre de charger les
modèles en RAM alors qu'utiliser un GPU se limitera à la mémoire vidéo
embarquée sur la carte, c'est à dire la VRAM. Enfin, il existe des
solutions logicielles qui permettent de cumuler CPU et GPU.
Pour ma solution d'hébergement, je voulais quelque chose qui permette
une inférence rapide en tant qu'assistant au développement mais aussi
une capacité mémoire permettant de faire tourner des modèles de taille
respectable le tout pour un coût relativement raisonnable.
Je me suis donc orienté vers une solution à base de deux
Nvidia RTX 3090 24GB. Ce matériel me permet de lancer des tâches
d'inférences rapides sur des modèles à 27b de paramètres. Ces GPU étant
des cartes graphiques destinées au jeu vidéo mais de génération assez
ancienne, cela permet de les trouver assez facilement d'occasion à prix
maîtrisé (compter tout de même dans les 600€ par carte).
Notez que je ne détaillerai pas le reste des caractéristiques du serveur
car cela importe moins pour le sujet de l'inférence IA, mais il faut
tout de même être attentif au nombre de ports PCIe disponibles et à la
génération (PCIe 4 ou 5) de ceux-ci. L'inférence n'est pas très
gourmande en débit et pour des cartes de cette génération vous pouvez
tout à fait vous contenter de ports PCIe 4 sur 8 pistes. De mon coté
j'ai utilisé un bifurcateur de port x16 vers 2x8 PCIe gen4.
Ce matériel devrait permettre de faire cohabiter aisément 4 développeurs
simultanément sur un gros modèle et jusqu'à 20 sur un petit modèle dédié
au code par exemple. Certains modèles sont en effet plus ou moins
gourmands en VRAM et/ou en capacité de calcul.

L'architecture logicielle
Le système d'exploitation
Une fois le serveur monté il est temps d'y installer un système d'exploitation. J'ai choisi d'utiliser Proxmox VE qui est une distribution linux basée sur Debian et dont l'objectif est de permettre de gérer facilement des conteneurs LXC et des machines virtuelles. L'architecture mise en place que nous allons détailler ci-dessous est la suivante :
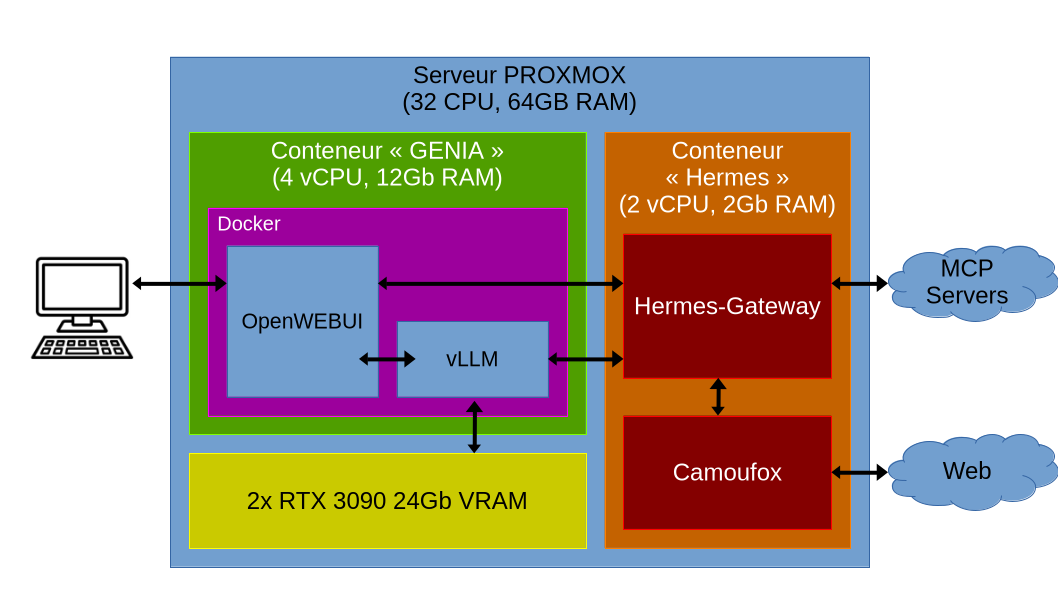
Conteneur "GENIA"
Le conteneur GENIA est une machine virtuelle qui héberge deux images
docker, son objectif est d'exposer vers l'extérieur l'interface
OpenWEBUI et d'exécuter le moteur d'inférence vLLM.
OpenWEBUI c'est l'interface web qui permet de saisir du texte et
d'obtenir des réponses de la part du LLM, il gère l'historique des
sessions, les éventuels prompt et sous-modèles ainsi que les comptes
utilisateurs et les droits d'accès.
Cette couche logicielle peut directement s'appuyer sur vLLM pour
interroger des modèles ou créer des sous-modèles via un prompt
customisé.
Elle peut en outre déclarer un sous-modèle qui ira interroger un agent
IA, dans notre cas nous allons utiliser hermes-agent qui est une
solution opensource.
Exemple d'interface web OpenWEBUI accessible depuis le navigateur :
vLLM est une plateforme technique qui permet d'exposer une api
pour télécharger puis exploiter un modèle au travers de différents
hardware, il reçoit les requêtes d'OpenWEBUI et execute l'inférence sur
les GPU puis répond. C'est à se niveau que nous pouvons déclarer le
nombre de GPU à utiliser, le modèle, la quantité de VRAM que l'on
souhaite allouer etc.
Voici quelques modèles que j'ai utilisé :
- NousResearch/Meta-Llama-3.1-8B-Instruct => Petit modèle facile
et léger, bien pour débuter.
- QuantTrio/Qwen3.5-27B-AWQ => Gros modèle du géant chinois
alibaba, intelligent mais assez gourmand en puissance de calcul.
- cyankiwi/gemma-4-26B-A4B-it-AWQ-4bit => Le dernier modèle de
chez Google, intelligent et efficace c'est le modèle que j'utilise
actuellement.
Notez que pour pouvoir charger en mémoire des modèles à 27b de
paramètres il est nécessaire d'utiliser des versions quantifiée 4bits ce
qui pour ces modèles ne représente qu'une perte de 1 à 2% de précision.
Conteneur "Hermes"
Le conteneur Hermes est une machine virtuelle légère dont le principal
objectif est d'isoler une instance d'agent IA Hermes. Cette isolation
permet de fournir à l'agent un environnement dans lequel il pourra
travailler en toute sécurité sans perturber celui du développeur et des
autres agents. Le conteneur isole aussi les accès à l'extérieur du reste
du serveur ce qui ajoute une couche de sécurité supplémentaire.
Ce conteneur execute l'agent hermes en mode "gateway" pour permettre
d'interagir avec l'interface d'openWEBUI. Il est également possible de
lancer un agent en mode "CLI" c'est à dire dans un terminal via SSH.
Pour accéder au monde extérieur, l'Agent peut échanger avec des serveurs
MCP, mais aussi des fourrnisseurs de messageries (Telegram, Whatsapp ..)
mais également avec le web traditionnel. Pour ce dernier l'agent est
souvent considéré comme un "robot" et bloqué par des captcha, pour
diminuer ce phénomène on ajoute un proxy "camoufox" qui émule un
navigateur lambda firefox afin de faire passer l'agent pour une
véritable personne physique.
Exemple d'interface Hermes en mode terminal :
Comparaison des coûts
Nous allons étudier le coût total de la solution afin de pouvoir
comparer avec le tarif des fournisseurs clé en main. Le duo de RTX 3090
consomme 800 watts en pic. Dans le pire des cas en opération soutenue le
serveur consommera donc 800w * 8h = 6,4kWh. avec un kWh à 20cts d'euros
cela donne une consommation d'à peu près
40€ par mois pour une utilisation intensive.
Le coût du serveur en tant que tel se situe au alentours de 2000€ (dont
1200€ de GPU). En prenant une durée de vie de 3 ans (36 mois) cela
ramène le coût du serveur à 55€ par mois.
Le coût total de la machine (achat+fonctionnement) est de environ
100€ par mois soit pour une équipe de 4 développeurs :
25€ par développeur par mois
Comparons maintenant les principaux tarifs fournisseurs pour les
abonnements "pro" :
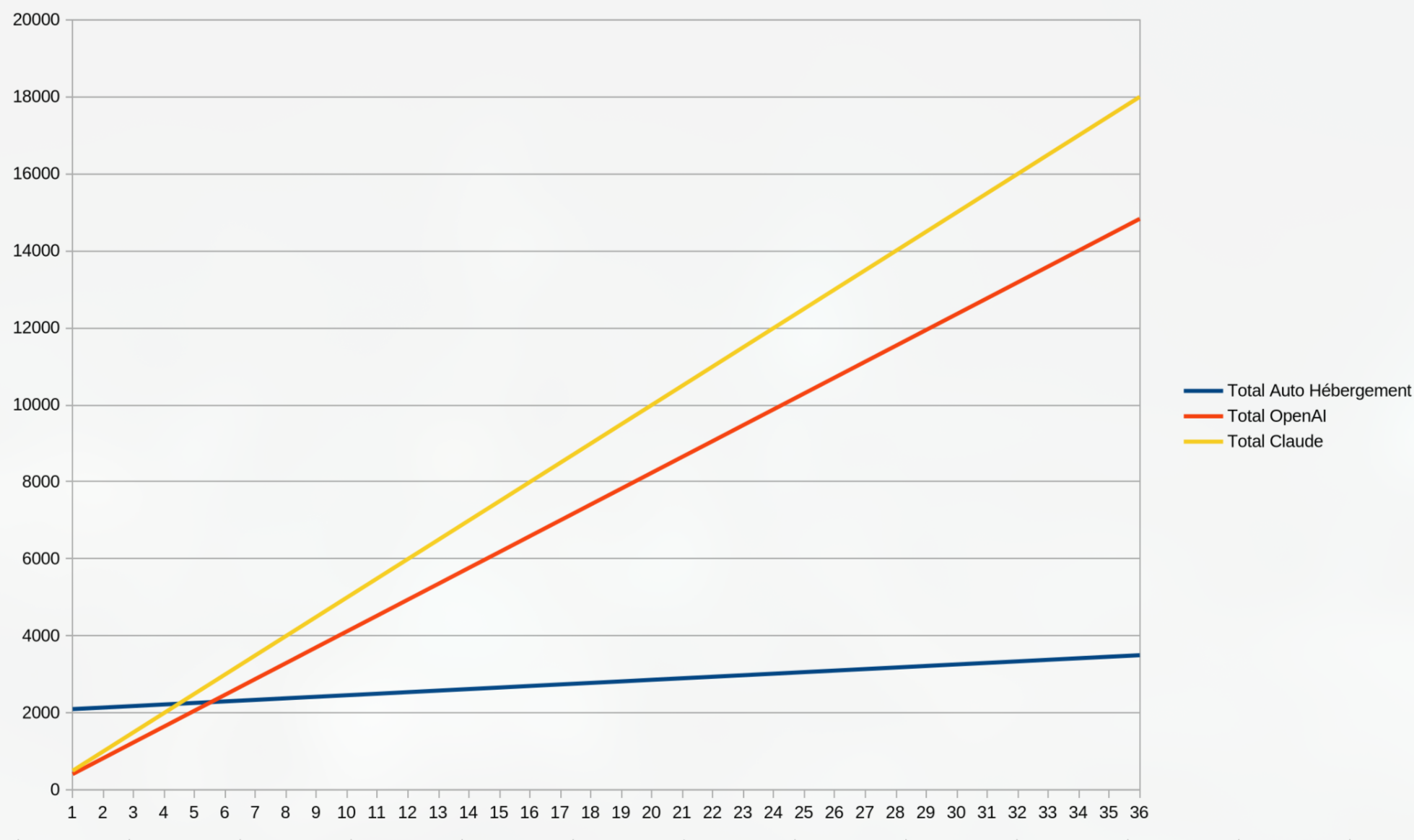
OpenAI Pro : 103€ par mois par développeur soit
412€ pour une équipe de 4
Claude : 125€ par mois par développeur soit
500€ pour une équipe de 4 développeurs.
Cela fait donc une différence d'à peu près 300€ par mois pour une équipe
de 4 développeurs permettant d'amortir le serveur en 6 mois.
Voici le tableau récapitulatif des coûts pour une équipe de 4
développeurs sur 36 mois:
Attention cependant, il y a quelques nuances à apporter à ce comparatif
:
- Un serveur nécessite une sauvegarde régulière, de la maintenance non
prise en compte ici de même qu'il subit la vétusté et nécessite la
réparation de pannes éventuelles.
- Les modèles "open weight" que l'on peut auto-héberger sont globalement
inférieurs aux modèles commerciaux même si sur des tâches spécifiques
(développement) la différence sera mineure, cela dépend donc de l'usage
et du niveau d'autonomie et d'intelligence attendu.
Comme nous l'avons déjà évoqué, un serveur local vous permet de garder
la confidentialité de vos données, usages et prompt. Il est donc crutial
d'évaluer la solution souhaitée en fonction du contexte, besoins et des
compétences de son équipe.
Démo
Démonstration de l'agent Hermes sur une analyse de dépot Github.
Conclusion
En conclusion, dans cet article nous avons abordé la mise en place d'un
serveur d'IA générative pour l'agentique en auto-hébergement. Il y a
évidemment de nombreux aspects de l'auto-hébergement qui ont été
volontairement laissés de côté pour se concentrer sur la mise en oeuvre
de la solution IA en tant que telle.
Cette solution pourrait à l'avenir être d'avantage explorée et
particulièrement en ajoutant des modalités d'échange avec l'agent (via
messagerie ou mail par exemple) ou des tâches automatisées (via cron).
Dans un futur proche je souhaite me pencher sur l'exploitation de ce
serveur pour de la génération de code via opencode et des modèles
dédiés.
Un autre aspect intéressant pour le domaine de l'entreprise sera
d'étudier le RAG c'est à dire le chargement des données métiers dans une
base de données vecteurs accessible via MCP.